Serverless Brain Dump: Use Lambda with RDS Aurora Serverless
Part 1 of 3 in a serverless discovery brain dump. This portion focuses on the Lambda (compute) and Aurora (database) layers within the larger picture: FQDN → API Gateway → Lambda → Aurora.
2022/04/06: Lambda now supports built-in HTTPS function urls. This sort of derailed the API Gateway portion, which I was planning for part 2 of this 3 part series.
2022/04/21: Aurora Serverless V2 is now generally available. One notable feature is that V2 clusters can be made available to the public, which was not possible with V1, so a greater portion of this article is not exactly relevant anymore.
A few thoughts:
Using a relational database with a serverless function has been frowned upon in my experience, specifically due to the concerns of multiple ephemeral functions spinning up and exhausting the database’s connection pool.
I’ve always wanted to use Postgres more on my deployed personal projects, but never enjoyed paying for a long running instance that received nearly no traffic (roughly $20/month for the smallest instance size), so I’ve always reached for DynamoDB instead.
Both of these prior thoughts drove me towards RDS Aurora Serverless, Amazon’s serverless relational database service. It can scale up with your traffic, and scale back down to zero when it is unused, costing you $0 if you have no traffic.
And again, not wasting money on something you’re not really using is always nice.
Prerequisite#
Typically when you create long running RDS instances, you’re presented with an option to make the database available to the public internet.
However, with Aurora Serverless, you do not get this option. Your database — well, cluster of databases — can only be accessed from within a VPC. This means that any sources of compute, like a Lambda function in this case, also need to exist inside that VPC.
VPC#
Specifying a VPC for a Lambda function can be accomplished through the AWS dashboard, or some programmatic way such as the AWS SDK, or an infrastructure-as-code tool like Terraform, but this on its own come with a couple requirements.
IAM Permissions#
In order to attach a VPC to a Lambda, the Lambda's execution role needs permissions
to call CreateNetworkInterface on EC2. This can be handled by attaching the managed IAM
policy, AWSLambdaVPCAccessExecutionRole, to the role.
AWSLambdaVPCAccessExecutionRolePolicy ARN:
arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRoleDescription:
Provides minimum permissions for a Lambda function to execute while accessing a resource within a VPC - create, describe, delete network interfaces and write permissions to CloudWatch Logs.
Permissions:
See this user guide.
Without this permission you’ll get the following error whether you’re attempting to attach a VPC via the console or SDK 1:
Specify Security Group IDs and Subnet IDs#
With proper EC2 permissions, updating the function's configuration 1 will now succeed both from the console and SDK.
In order to actually specify a VPC for a Lambda function, you need to select security group IDs and subnet IDs.
Below is a script that I wrote in go to automate all the would-be manual
clicking of this process.
Helper Script#
The inputs...
| Parameter | Description |
|---|---|
lambdaArn | The ARN of the Lambda function to update. Security Group IDs and Subnet IDs can be derived from this. |
vpcId | The ID of the VPC to attach to the Lambda |
roleName | The name of the Lambda’s execution role |
💭 Looking back, maybe
roleNamecan be derived fromlambdaArn.
The code...
The logic flow is roughly:
- Get subnets for a given VPC ID
- Get a single security group for a given VPC ID
- Attempt to update the Lambda’s configuration with these Values
- Check for failure; Attempt to attach the IAM policy to the Lambda’s execution role
- Retry step 3
After this configuration update is applied, the Lambda function will be able to
connect to the Aurora Serverless cluster through your typical language-specific
clients, like node-postgres.
What about connection pooling?#
I ran an end-to-end test with an open source HTTP load gnerator (go based),
on my FQDN → API Gateway → Lambda → Aurora integration 2. What I observed
was that up to 1,000 concurrent lambda functions 3, the Aurora Serverless
cluster appeared to autoscale up fine.
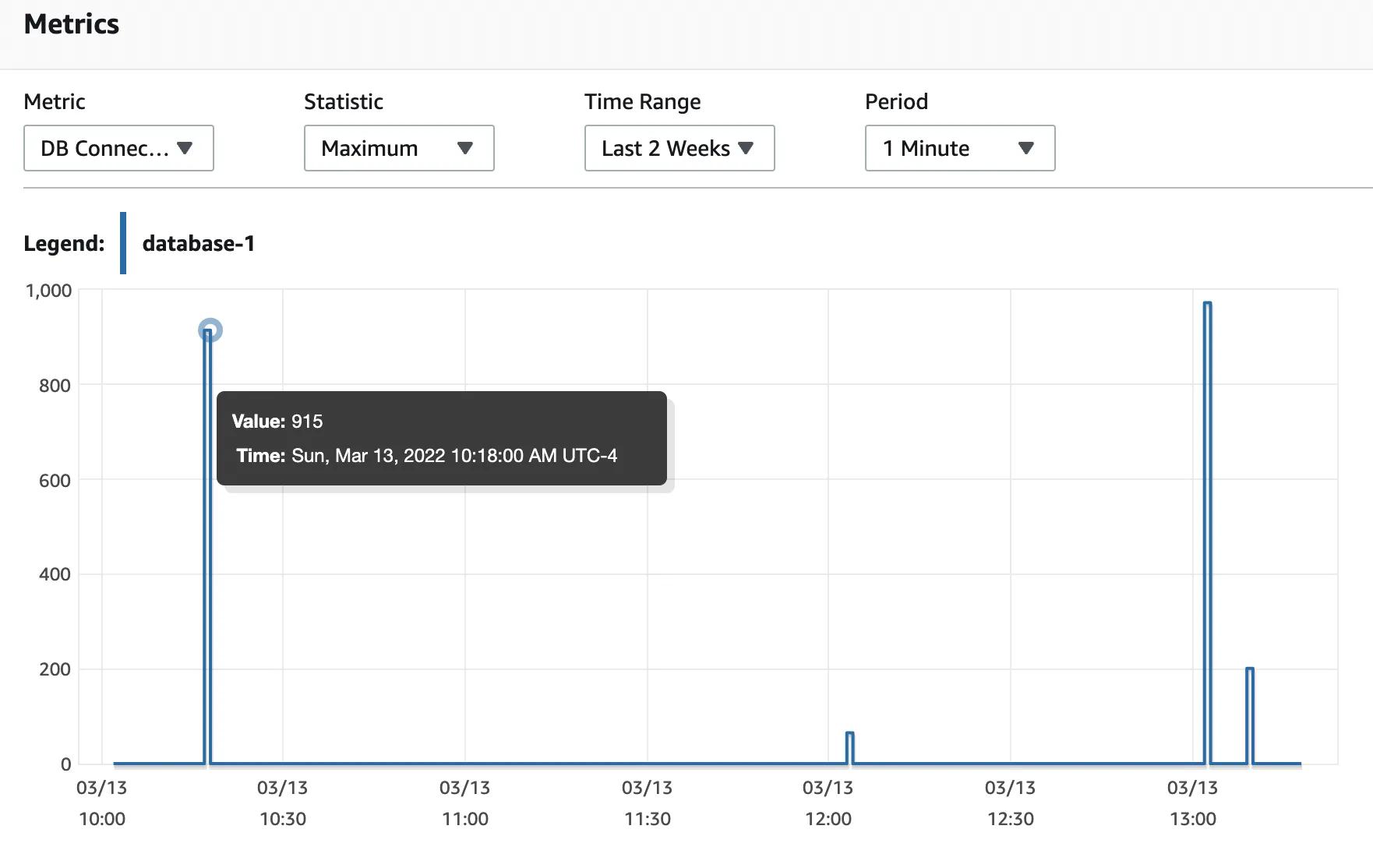
But this crude testing was done on a single Apple M1 Max computer, so take it with a grain of salt.
More brain dumpage coming soon...
Got any feedback?
Feel free to leave any comments, questions, suggestions below in the new comments section, powered by utterances 🔮
Footnotes#
-
Updating a Lambda’s configuration executes
lambda::UpdateFunctionConfigurationunder the hood. ↩ ↩2 -
I’ll write about the full FQDN → API Gateway → Lambda → Aurora integration in the next two posts. ↩
-
1,000 is the default concurrency limit set by AWS. ↩