Tree CLI & Benchmarks
(Re)creating a CLI tool to print directory contents in a tree-like format. And then some benchmarking.
Overview#
I've always known about the tree CLI, but had never thought about how it worked.
I also hadn't done much work around command line interfaces or file systems . But recent
work at HashiCorp nudged me to become more fluent in code
dealing with the latter.
I decided to recreate the existing CLI in Golang.
Prior art: https://github.com/MrRaindrop/tree-cli
Every, if not all, programming language has a standard library that includes
a basic file system API. The tree CLI is written in JavaScript and
leverages Node.js's fs module.
Here are some examples for other languages.
- Go: os.ReadDir
- Rust: fs::read_dir
- Python: os.scandir
Algorithms#
I didn't bother looking at the tree source code since I wanted to
tackle this from the ground up. The only reference I had was the output since
that was what I was aiming to reproduce.
What I thought was going to be a fun time writing Go, turned into a whiteboard coding exercise with a ton sanity checks via benchmarks, and ironing out bugs and false positives. All in all, it was pretty challenging.
The easy part#
The two patterns for traversing tree and graph data structures are depth-first
and breadth-first. I wanted to print a line to stdout
for each node while retaining the tree structure so breadth-first was
the appropriate approach.
Depth-first involves reaching the end of a subtree before backtracking and repeating the same for sibling subtrees. Recursion is the most common way to implement depth-first traversal.
Breadth-first involves visiting all nodes at the current depth before moving one level deeper and repeating. This is commonly implemented iteratively with the help of a queue and a loop.
Here is the output from the first pass at implementating tree in Go.
Recursively visiting all nodes and printing their names with indentations based on depth was easy enough.
But things quickly became tricky when I needed to include what I'll
refer to as the symbols — branches (│···), stems (├──), corners (└──),
and spaces (····).
The tricky part#
Nailing down the pattern to how the symbols were generated was challenging, especially while also learning a new set of APIs in a fairly new language.
I arrived at multiple implementations, with and without optimzations, with each improving upon the former with regards to speed.
Abandoned Solution#
I originally settled on this approach, feeling pretty good, and began writing this post. But I had one of those overnight epiphanies that there must be a simpler and more efficient solution.
This strategy to draw the symbols came in two parts.
- A node needs to know if it itself is the last element amongst its siblings. This is required in order determine whether to draw a corner (
└──) or a stem (├──) for the tip of the branch.- The rest of the symbols require traversing backwards, or up the tree. If a parent was the last amongst its siblings, draw an empty space (
····), otherwise draw a stem (│···).While this worked fine, the backwards traversal was convoluted and warranted a refactor.
I'll leave this here for posterity... Mostly as a fun reminder to my future self.
Actual Solution#
From a cognitive-load standpoint, I wanted to keep the logic flow as forward-moving as possible. I wanted to avoid building symbols backwards since it an unnecessary complication that likely had an alternative that was easier to reason about.
For each folder and file, I would build the string of symbols in a forward direction.
- For each path segment leading up to the base
(the last element of the path), I'd check if the path segment was the last entry
amongst its siblings. If so, append a space (
····) to the string of symbols, else append a stem (│···).- I would also cache this result since it would be calculated multiple times for files sharing the same path segments.
- For the base segment, I'd check if it was the last entry amongst
its siblings. If so, append a corner (
└──) to the string of symbols, else append a branch (├──).- Given that absolute paths to folders and files are globally unique, the resulting symbol for the base segmen would not need be cached because the calculation would only occur once.
Here is the output from the current and final implementation.
I was pretty happy with this result, so I moved on to see if any improvements could be made.
Benchmarks & Optimizations#
Golang has built-in benchmarking, which is a huge win over Node.js.
This was my first time using any sort of benchmarking feature and it was helpful in revealing the impact that different code choices had on performance.
When running benchmark tests, Go outputs 2 numbers.
- The first (
532) is the number of times a test ran in order for go to establish a stable average.- The second (
2247587 ns/op) is the average time it took to run a test.Golang automatically determines how many times to run a benchmark test. (Docs)
Optimization#
The major optimization that I applied was simply writing code that didn’t suck. In more specific terms, I removed logic that was confusing to reason about, and unnecessary helper functions.
Beyond that, micro optimizations like caching repeated computations helped to improve benchmark times.
But stressing this again, writing code that didn’t suck was the biggest performance boost. I came to this conclusion a bit late, after the 3rd iteration, and 80% through the first draft of this write up.
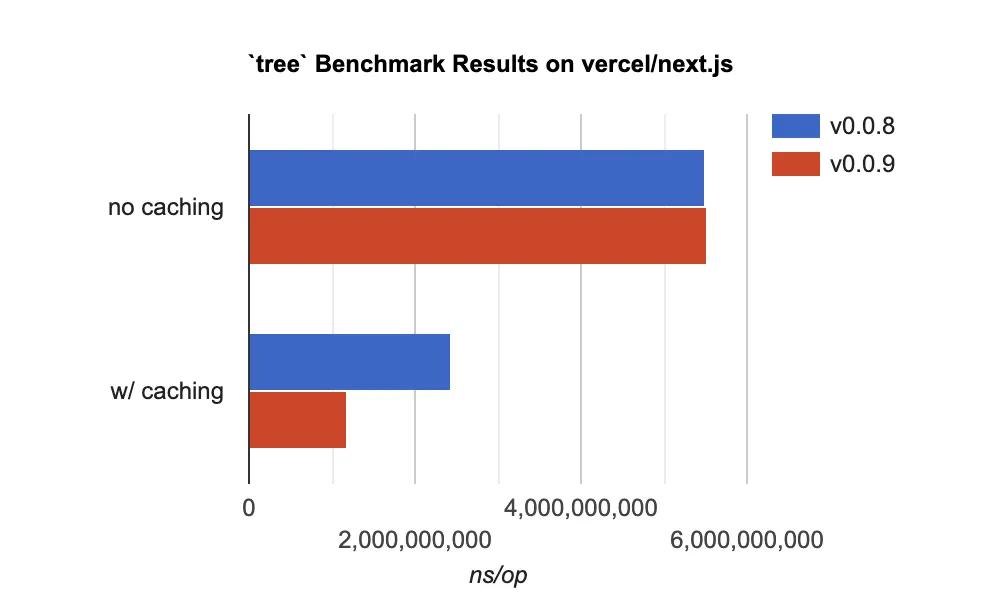
Results#
Here is a series of benchmark results of my tree command run against two different
trees of files.
- thiskevinwang/tk
- Files: 24, Folders: 5
- See benchmark name:
BenchmarkTreeTk-12
- vercel/next.js
- Files: 7523, Folders: 3395
- See benchmark name:
BenchmarkTreeNextJs-12
As a side note, Go benchmark tests can be run with the -bench=. flag.
Previous implementation#
The first two results are from the code I ended up
abandoning — (v0.0.8)
Current implementation#
These next two results are from the updated implementation —
(v0.0.9)
v0.0.9; no caching
v0.0.9; w/ caching
Here's a chart comparison of the two implementations.
Closing thoughts#
Getting the quick-n-dirty, first iteration of this tree command out the door was fairly easy.
However, it performed quite slow because it was copying the file tree data into a home-baked
Node struct which had
an unhealthy amount of extra fields. Before I understood more of the os
& filepath API's, this struct was easier to reason about.
The first big refactor to remove this struct was also relatively easy. It just involved reading some API docs, perservering through some code changes, and boom... performance improvements.
The real challenge came when I needed to further simplify my own previous logic... AND THEN provide supporting evidence that it indeed was more performant. This required me to have a significantly more disciplined development process.
I needed to keep track of several versions of the code — old, new, and both with and without caching — and constantly benchmark them, not introduce any regressions or bugs, and also consider false positives when benchmark results seemed too good to be true.
<Note> vs. markdown > blockquotes...This CLI is published to GitHub using GoReleaser, and is available as a Homebrew formulae.
The source code for the specific
treecommand is at: thiskevinwang/tk/cmd/treeInstallation (homebrew)